



决策树算法-C4.5算法

一、C4.5算法介绍
C4.5算法是对ID3决策树算法的改进,之所以要改进ID3算法,主要有以下原因:,信息增益倾向于选择取值多的特征,当特征取值多时,D被划分为多个子数据集,每个子数据集中的样本数可能比较少,里面只包含单一类别样本的可能性就比较大,这样就会导致条件熵比较小,从而使得信息增益比较大,在极限情况下,特征A的取值特别多,以至于每个样本都有一个不同的取值,这样每个子数据集就只含有一个样本,每个子数据集的类别都是确定的。比如:以毫米为单位的发长特征。(本质上还是数据量不足)
改进思想:
- 相对信息增益,即:信息增益率
- 用信息增益率代替信息增益选择特征
分离信息:
- 分离信息也是一种熵,按照
特征取值计算概率,不是按照分类结果计算概率:
信息增益率:
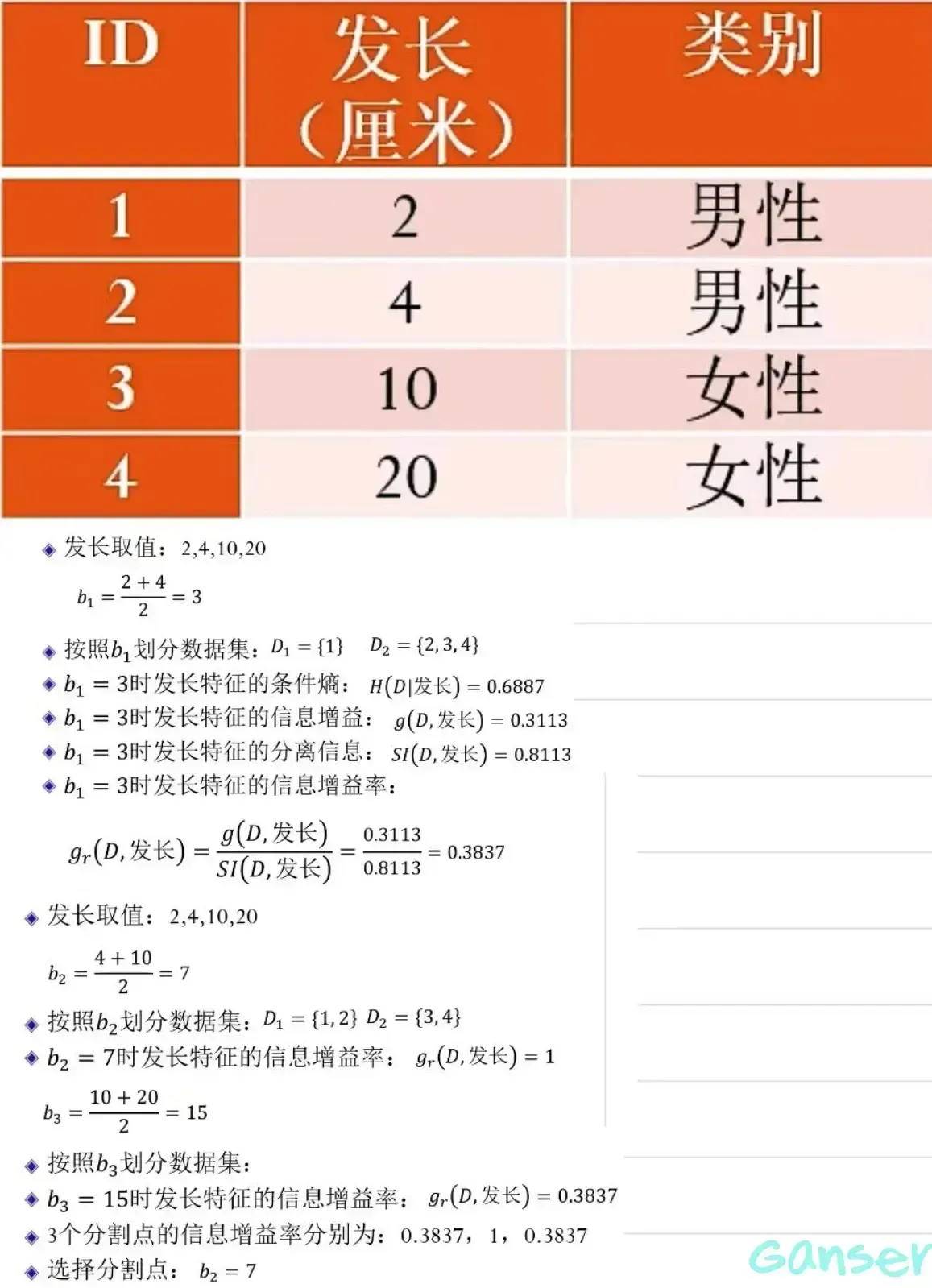
二、计算举例

三、C4.5算法改进
C4.5算法不仅通过引入信息增益率改进了决策树特征选取的方法,而且引入连续特征(允许特征取值连续)。
处理方法:
- 按照特征A的取值对数据集D中的样本从小到大排序,第i个样本特征A的取值为
- 按照值将D划分为2部分
- 计算信息增益率
- 最大的信息增益率为特征A的信息增益率
注意:特征取连续值时,并不是只能使用一次。
C4.5算法也存在不足,它倾向于取值不平衡的特征。改进方法为:从n个信息增益大的特征中选择信息增益率最大的特征,n的确定是根据信息增益大于平均值的特征。


本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 GanSer!
相关推荐






评论
匿名评论
✅ 你无需删除空行,直接评论以获取最佳展示效果



