



统计学习方法实现分类和类聚(三)-随机森林算法

一、决策森林算法
利用决策树算法,在训练样本足够多的情况下,我们通常可以将大训练样本划分为多个子数据集,通过对每个子数据集构建决策树来构建决策森林。因为每个子数据集相互独立,因此不同子数据集构建的决策树也相互独立,将这些相互独立的决策树横向合并并将待分类的样本送入不同的决策树,针对每个决策树的输出,即以投票的方式最终确定待分类样本的类别。
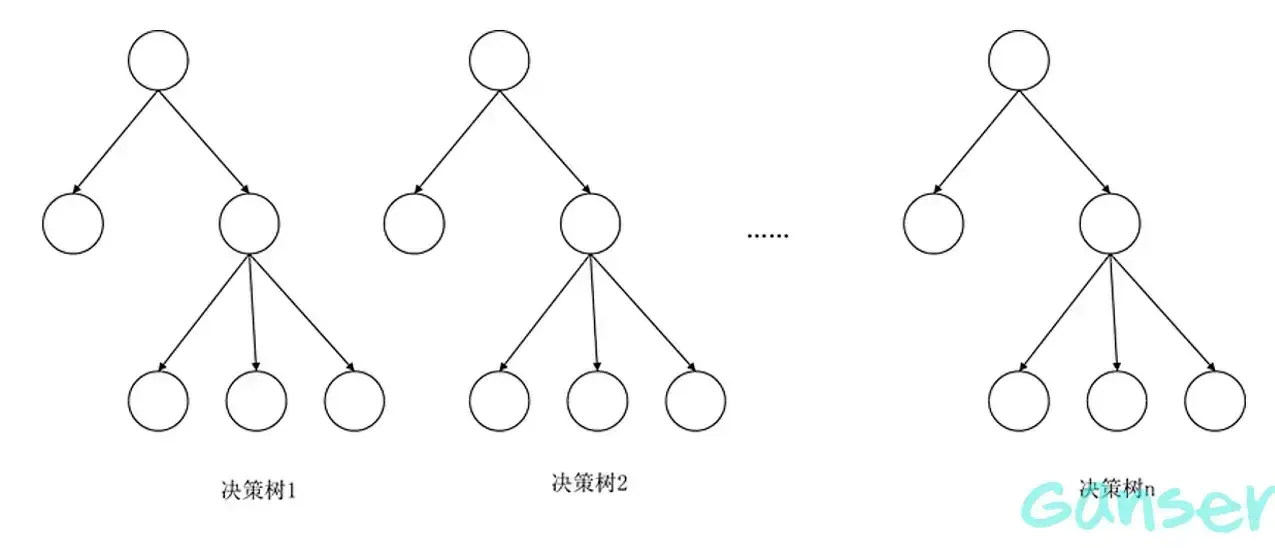
可见,决策森林的建立依赖大量的数据,但往往数据的量总是不足,为了解决这一问题,提出随机森林算法。
二、随机森林
2.1 重复采样
为了解决数据不足的问题,利用有限数据建立尽可能多的决策树,采用重复采样的办法:
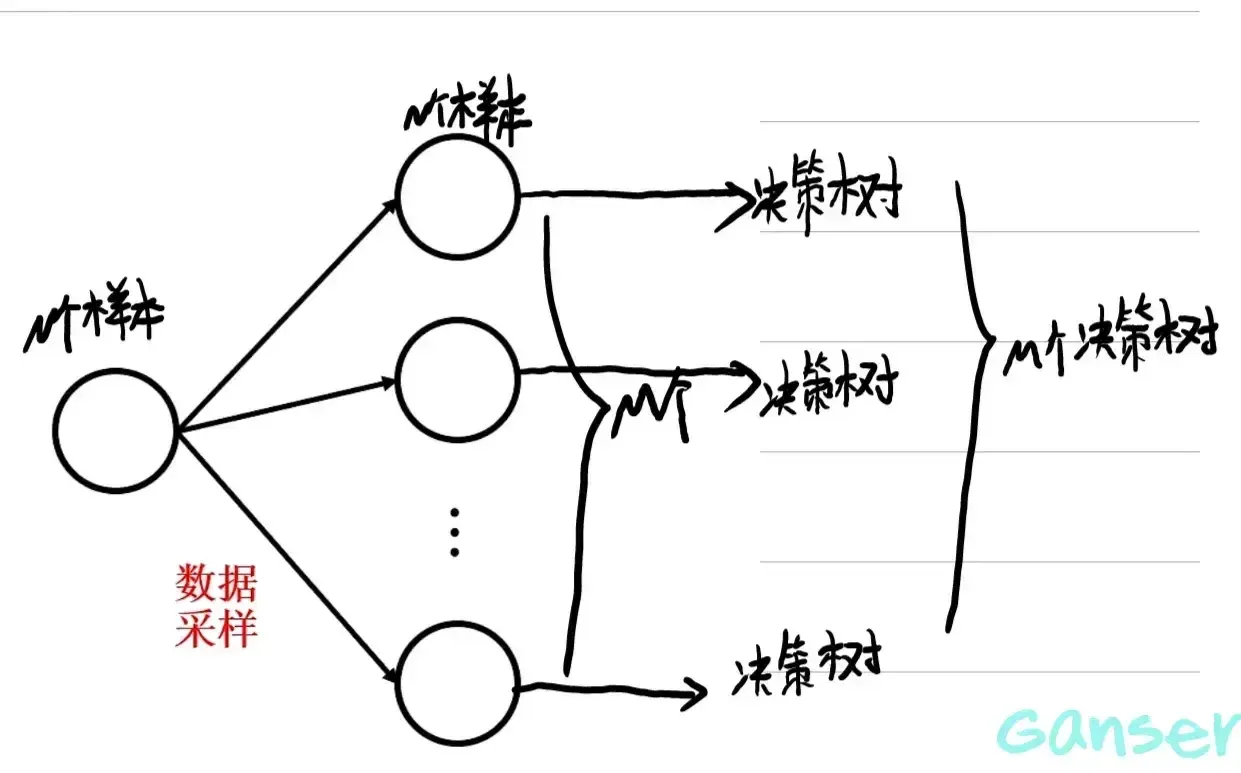
这里体现了随机森林算法的随机性,在重复采样的过程中,新生成的包含同样样本个数的子集是随机采样得到的,但是由于M个新数据集均来自同一数据集,因此各个新数据集之间仍不是独立的。这里引入特征采样解决这一问题。
2.2 特征采样
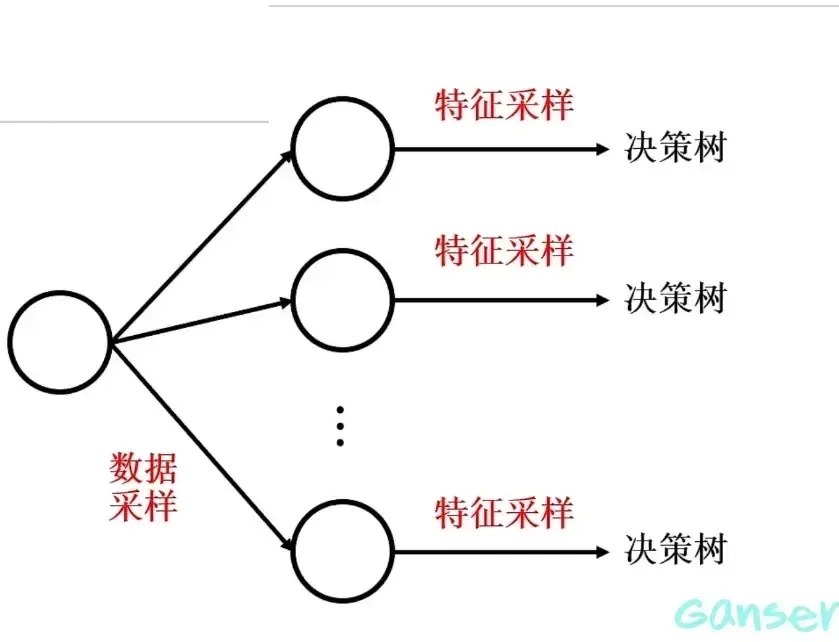
在特征采样的过程中,对于同一个特征集的特征样本不采用重复采样,这样就保证了决策树的独立性。
2.3 森林的规范性
考虑森林大小:太小投票机制作用有限,但是太大决策树之间缺乏独立性,因此要选择一个合适的大小(依据为在测试集中的错误率最小)。若没有测试集,我们可以使用集外数据。
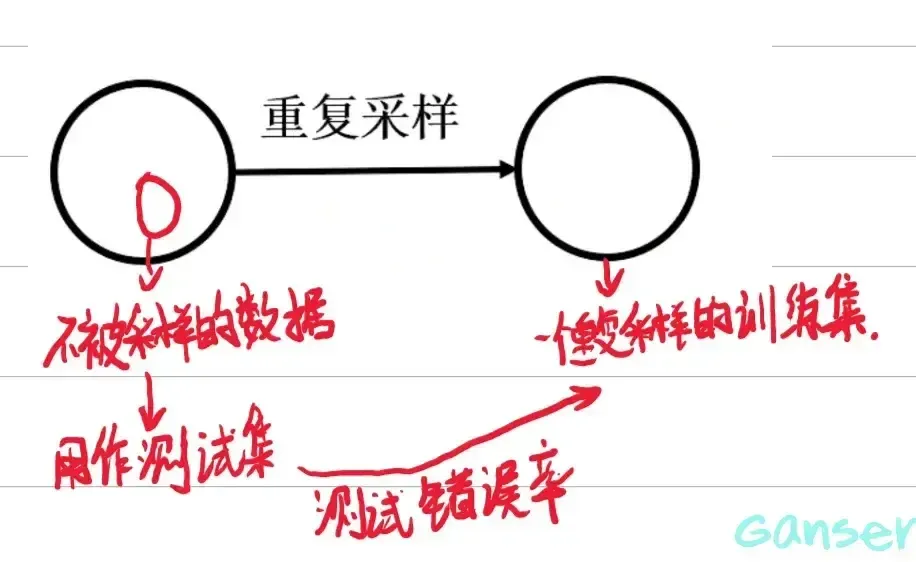
利用集外数据确定最小错误率时的森林大小,使随机森林具有很好的性能。


本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 GanSer!
相关推荐






评论
匿名评论
✅ 你无需删除空行,直接评论以获取最佳展示效果



